

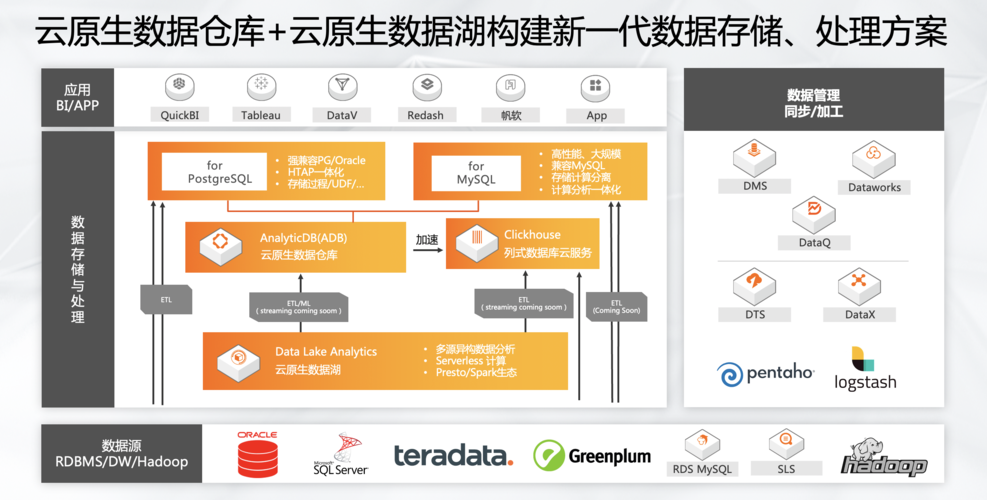

【云数据仓库ADB数据量初期不会很大,没有必要设置分区键,但是后期数据量会逐步增大,如何处理?】
在云数据仓库ADB中,当数据量逐渐增大时,可以考虑以下几种处理方式:
1、分区键的设置:
分区键是用于将数据分散存储在不同的物理区域或节点上的一种机制,通过合理设置分区键,可以提高查询性能和数据的并行处理能力。
在数据量较小的情况下,可以不设置分区键,因为此时数据量较少,查询和处理的压力相对较小。
随着数据量的增加,可以根据业务需求选择合适的分区键进行设置,常见的分区键包括时间、地域、用户ID等。
2、水平扩展:
当数据量增大时,可以通过增加节点的方式实现水平扩展,以增加系统的处理能力和存储容量。
水平扩展可以提高系统的并发处理能力,并能够更好地应对大数据量的需求。
在云环境中,可以根据需要动态调整节点数量,以满足不同阶段的数据量需求。
3、压缩和归档:
对于历史数据或者不经常访问的数据,可以进行压缩和归档处理,以减少存储空间的占用。
压缩可以减少数据的存储空间需求,提高存储效率;归档可以将不活跃的数据移动到低成本的存储介质中,降低存储成本。
可以使用云平台提供的压缩和归档工具,对数据进行相应的处理和管理。
4、索引和优化:
当数据量增大时,可以考虑建立合适的索引来提高查询性能。
索引可以加速数据的检索过程,提高查询的效率,根据具体的查询需求,可以选择创建单列索引、多列索引或者全文索引等不同类型的索引。
还可以对查询语句进行优化,使用合适的索引和连接方式,以提高查询的性能。
5、监控和调优:
随着数据量的增加,需要定期监控数据仓库的性能指标,如响应时间、并发数等。
根据监控结果,可以对系统进行调优,如调整节点配置、优化查询语句等,以提高系统的性能和稳定性。
可以使用云平台提供的监控工具和日志分析工具,对系统进行实时监控和分析。
与本文相关的问题:
1、如何选择合适的分区键?
答:选择合适的分区键需要考虑业务需求和查询模式,可以根据数据的访问特点和查询频率选择适合的分区键,如果数据按照时间顺序访问较多,可以选择时间作为分区键;如果数据按照地域分布访问较多,可以选择地域作为分区键,还需要考虑分区键的选择对查询性能的影响。
2、如何进行水平扩展?
答:进行水平扩展可以通过增加节点的方式实现,需要评估当前系统的处理能力和存储容量是否满足需求,根据需求选择合适的节点类型和数量,并进行节点的添加和配置,在云环境中,可以根据需要动态调整节点数量,以满足不同阶段的数据量需求,还需要对新添加的节点进行负载均衡的配置和管理,以确保数据的均匀分布和查询的并发处理能力。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/464140.html
 微信扫一扫
微信扫一扫