

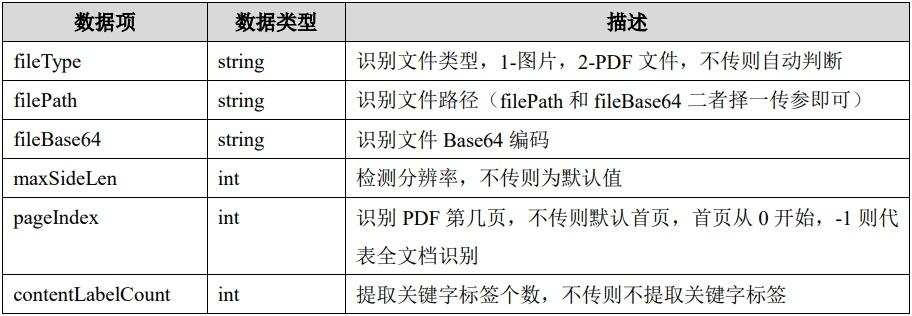

文字识别OCR(Optical Character Recognition)是一种将纸质或图像中的文字转换为可编辑文本的技术,在处理表格信息时,准确率可能会受到影响,为了提高文字识别OCR在表格信息抽取方面的准确率,可以采取以下调整措施:
1、优化图像质量:
使用高分辨率的扫描仪或相机进行图像采集,确保图像清晰度。
调整光线和对比度,使表格内容更清晰可见。
2、预处理图像:
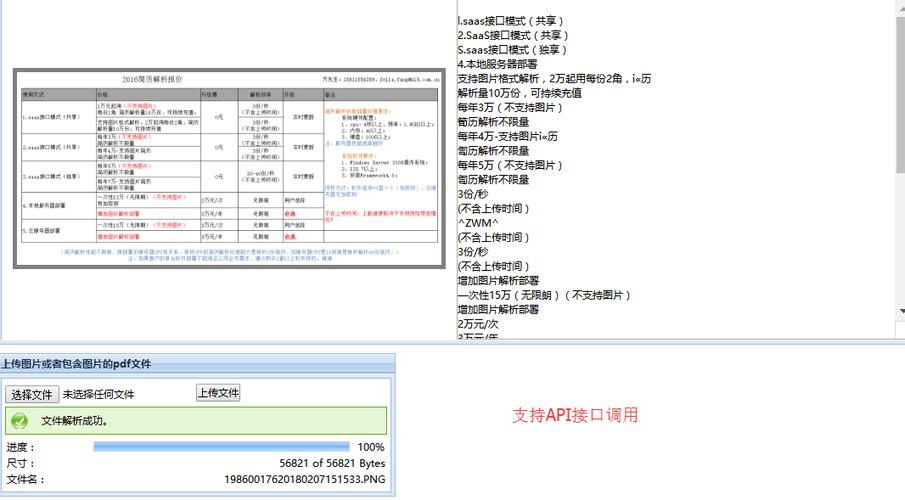
去除图像中的噪声和干扰,例如通过平滑滤波器。
对图像进行二值化处理,将背景与文字分离。
3、表格检测与定位:
使用表格检测算法,如连通区域分析、边缘检测等,来定位表格的位置和大小。
根据表格的结构特点,如行列线、标题行等,进一步细化表格的定位。
4、文字分割与识别:
对每个单元格内的文字进行分割,可以使用基于规则的方法或机器学习算法。
针对每个单元格的文字进行识别,可以使用OCR引擎或自定义训练的模型。
5、后处理与校正:
对识别结果进行后处理,如去除多余的空格、纠正拼写错误等。
结合上下文信息,对可能的错误进行校正,例如根据相邻单元格的内容推测缺失的文字。
6、优化模型参数:
根据实际应用场景,调整OCR引擎或自定义模型的参数,以提高准确率。
使用更大的训练数据集,增加模型的泛化能力。
7、结合其他技术:
结合语义理解技术,对表格中的数据进行结构化处理,提取更丰富的信息。
结合自然语言处理技术,对表格中的文字进行语义分析和推理。
8、用户反馈与迭代:
收集用户的反馈和标注数据,用于改进模型和算法。
不断迭代和优化系统,提高准确率和用户体验。
通过以上调整措施,可以提高文字识别OCR在表格信息抽取方面的准确率,仍然可能存在一些挑战和限制,例如复杂的表格结构、低质量的图像等,需要根据具体应用场景和需求,灵活选择合适的方法和技术。
问题1:如何应对复杂的表格结构?
对于复杂的表格结构,可以考虑以下解决方案:
使用更先进的表格检测算法,能够准确定位和分割复杂的表格结构。
结合语义理解技术,对表格中的数据进行结构化处理,提取更丰富的信息。
使用机器学习算法,通过训练模型来自动识别和处理复杂的表格结构。
问题2:如何处理低质量的图像?
对于低质量的图像,可以考虑以下解决方案:
使用高分辨率的扫描仪或相机进行图像采集,确保图像清晰度。
在预处理阶段使用去噪和增强算法,提高图像质量。
结合上下文信息和语义理解技术,对低质量图像中的文字进行更准确的识别和校正。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/464499.html
 微信扫一扫
微信扫一扫